


- Research platform
Sources of information
Data analysis
Actions

- Solutions
For whom
Problems / Issues

- Materials
Materials
- About us
About us
Automatic categorization of survey statements is a process in which a computer system analyzes text data and assigns it to appropriate categories without the need for manual reading and analysis. By using advanced machine learning and artificial intelligence algorithms, automatic categorization allows for efficient management of large amounts of information, which is particularly useful in market research, surveys or opinion analysis.
Why is it important? First of all, automatic categorization saves time. Manually assigning responses is time-consuming and prone to errors, while automating the process allows for quick and precise assignment of data. It also increases operational efficiency, enabling companies to make faster decisions and better manage resources. Finally, it improves the accuracy of data analysis, minimizing the risk of human error and leading to more accurate reports.
Categorization automation can be approached in two ways:
Choosing the right tool for automatic categorization is crucial to the efficiency and accuracy of the process. Below are some important criteria to consider when choosing a tool, and examples of popular solutions available on the market.
An example of a research tool that provides automated processing is YourCX
YourCX is a platform focused on analyzing customer experience and conducting any research, which offers automatic categorization of open-ended responses and sentiment analysis.
Platforms like Medallia and Qualtrics also have similar capabilities.
Automated categorization of open responses requires properly prepared data that can be analyzed. Data sources can be diverse:
In order for data to be effectively analyzed by automated categorization tools, it is important to determine when and in what situation the data was collected. This is needed in order to give the right context for content analysis mechanisms. For example, it is important here:
If you don't have predefined categories to begin with, YourCX allows you to automatically generate categories based on text analysis. This is a quick and 100% automated solution:
In a very short time, you can find out what respondents are writing about and pull out business-relevant topics.
To ensure that the model is trained accurately, it is necessary to prepare the training data properly. After all, we want the categorization model to work exactly as we expect it to. The better examples we provide, the better the mechanism will work in the future.
What to pay attention to and what to do:
Import existing reviews that have already been categorized manually. You can do this directly through YourCX data importer. Real examples of manually categorized statements will be a very good input for the categorization model.
Categories should be logically separated if you want to have a low proportion of categories assigned redundantly. Examples of close categories are reliability and failures or availability and locations. However, if it is acceptable to assign several categories to a statement, close categories can be left.
Include all aspects of the topic
Categories should cover all aspects that may appear in a topic. If we want to be able to break out categories for problems, there should also be categories for praise for similar topics or general categories. Otherwise, it will be the case that promoters praising a mobile app could be assigned the category "mobile app performance problems." However, if the model is to work only on critical statements, it can target only problems. This is also related to the prior analysis of the purpose and context of the question being analyzed.
Generating training data
If you don't have enough self-categorized opinions, YourCX provides mechanisms to generate additional opinions automatically to provide enough training data. With just a few clicks, you can generate thousands of diverse statements used to train a categorization model. By automatically preparing training statements, you can save dozens of hours.
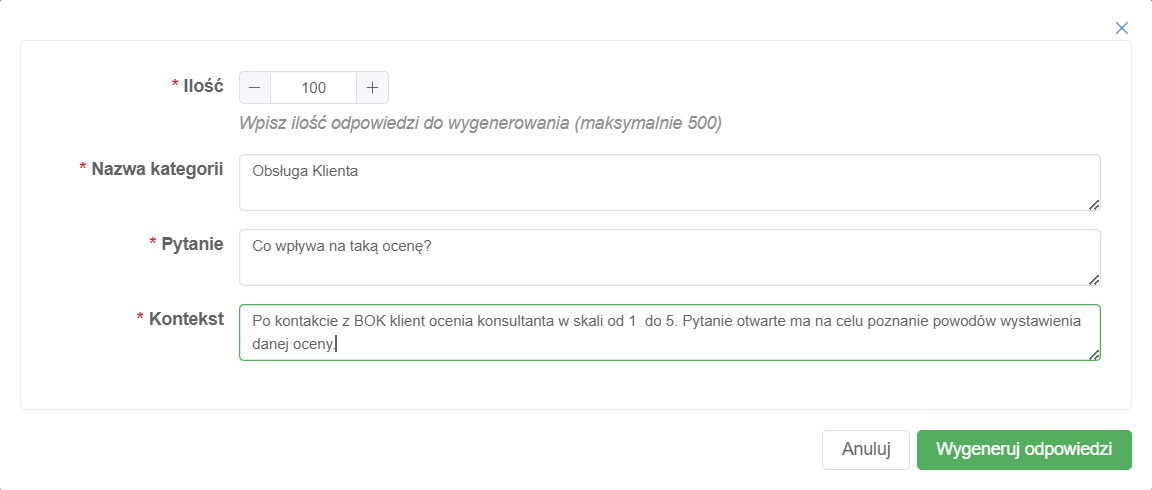
Remember - generate synthetic statements and add manually categorized statements so that each category has a minimum of 200 examples. The better the examples, the better the categorization model will work.
Training the categorization model in YourCX is the step that creates a viable mechanism and language model that assigns categories according to your expectations.
Train the model based on imported or generated feedback. YourCX will automatically adjust the model parameters to achieve the best possible accuracy. However, if you think it would be useful to change the training parameters - you can influence everything. Examples of parameters you have influence over are:
Once the model has been trained, it is necessary to evaluate its quality to ensure that it works properly and categorizes opinions effectively.
Testing the model: The model is automatically tested on a training dataset. If you would like to test on an additional validation dataset, just import it and the analysis will be performed automatically.
Evaluation metrics: Use metrics such as accuracy (accuracy), precision (precision), sensitivity (recall) and F1-score to evaluate the quality of the model.
Error checking: Identify and analyze cases miscategorized by the model (if any). YourCX allows you to easily review and analyze such cases, as well as edit categories.
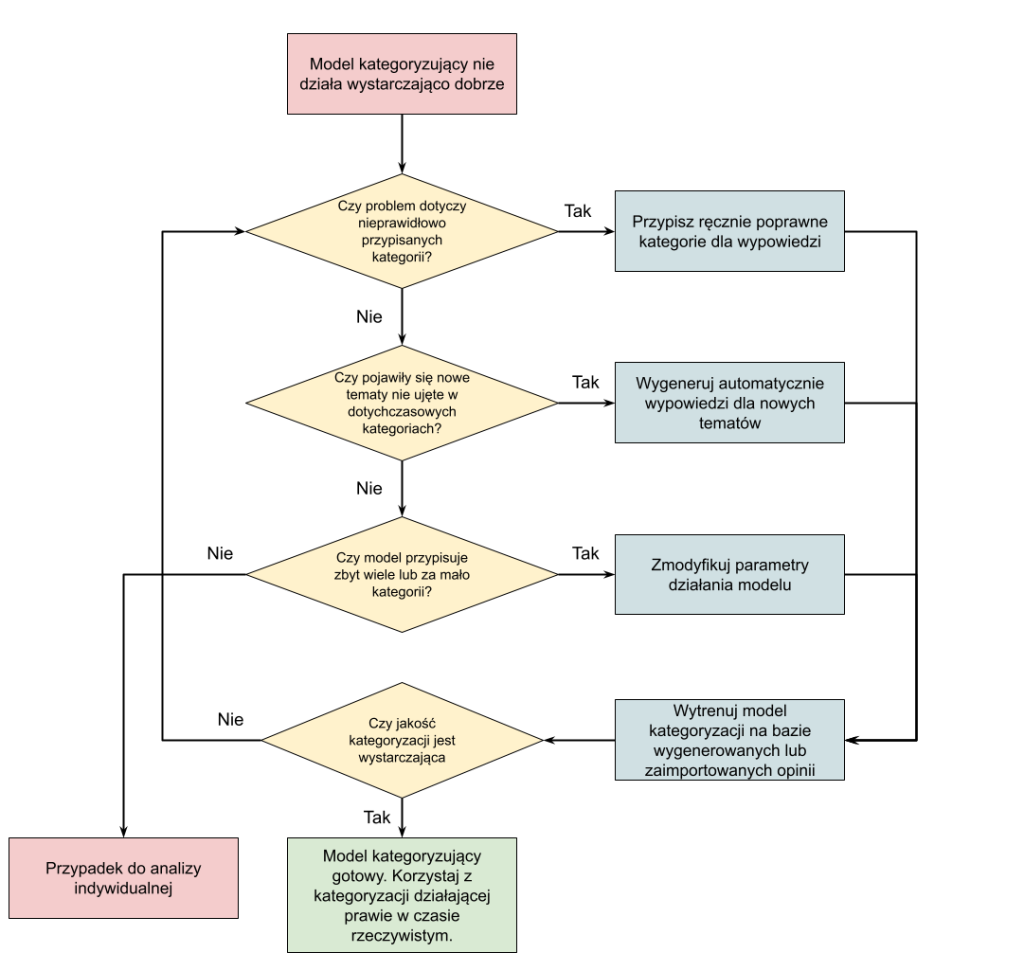
If the model is not working well enough, YourCX offers full support for any problem or discrepancy cases to optimize
Correct the categories
If the problem is related to incorrectly assigned categories, manually assign correct categories for the problematic statements.
Adding new categories
If there are new topics that were not included in the existing categories, generate additional feedback for these topics to expand the model.
Modify parameters
Modify the model's performance parameters, such as the loss function, to change the model's quality of operation.
Manipulate probability acceptance thresholds
The working model determines probabilities for all categories. By setting the thresholds high enough, you can get rid of over-assigned categories. However, on the other hand, the risk of eliminating the correct category also increases.

Above you can see the confusion matrix, which informs about potential problems with category assignment.
Re-training: Train the model again on the revised and new data to achieve better results.
Categorizing statements is not enough. With sufficiently general and separable categories, it is worth analyzing the sentiment and emotions in the statements to know which are positive and which are negative. YourCX offers this type of solution off-the-shelf, allowing you to automatically analyze the distribution of emotions and sentiments for business-relevant issues, as well as get alerts for critical remarks, e.g. about Customer Service.
Sentimentanalysis:
Use sentiment analysis tools in YourCX to determine whether feedback is positive, negative or neutral. This will help you better understand customer sentiment.
Emotion analysis:
YourCX allows you to identify emotions expressed in reviews, such as joy, anger, sadness, surprise, etc. Integrating the results of emotion analysis with categorization gives a more complete picture of customer feedback.
Integration of results:
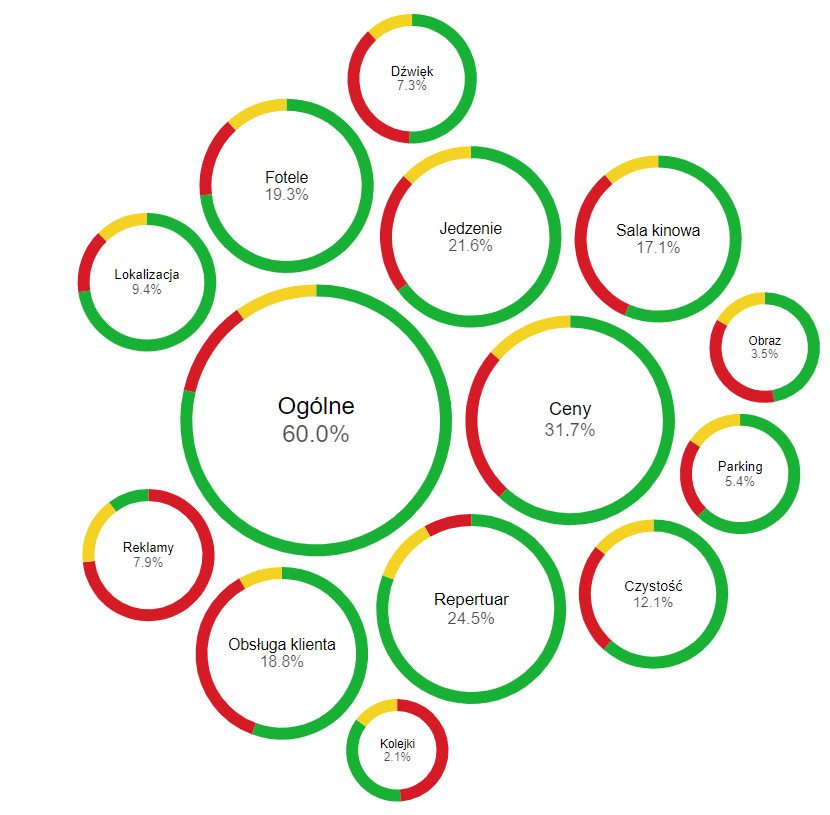
Integrating sentiment and emotion analysis results with categorization produces more detailed and valuable data for analysis. As an example, the following shows Google Maps opinion data processed automatically with automatic satisfaction ratings for each issue and the percentage for that issue.
If you are interested in the topic and would like to save time on analyzing survey or opinion data, let's talk.
Copyright © 2023. YourCX. All rights reserved — Design by Proformat
